🧭 Uvod: Gdje smo i kuda idemo?
Prije nego što naučimo kako koristiti ChatGPT ili Claude u poslovnom okruženju, moramo razumjeti kako oni zapravo rade. Ovo nije teorija radi teorije — kada budete podešavali API parametre, dizajnirali prompts ili procjenjivali troškove, ova znanja su od direktne koristi.
Danas ćemo odgovoriti na pitanja:
- Zašto ChatGPT razumije kompleksne rečenice, a stari chatboti nisu mogli?
- Šta je to Transformer i zašto je revolucionisao AI?
- Kako računar pretvara tekst u matematiku i nazad u tekst?
- Šta su to tenzori, vektori i embedding?
📜 Evolucija NLP-a: Od Rule-Based do Transformera
Da bismo razumjeli zašto je Transformer revolucionaran, moramo vidjeti odakle dolazimo. Natural Language Processing (NLP) — automatska obrada ljudskog jezika — razvijao se decenijama.
1950-e — 1990-e: Rule-Based sistemi
Rani chatboti (poput ELIZA, 1966.) radili su na osnovu unaprijed napisanih pravila: "Ako korisnik napiše 'zdravo', odgovori sa 'Dobar dan!'" Ove sisteme su pisali programeri ručno, pravilo po pravilo. Bili su lomljivi — svaka varijanta pitanja zahtijevala je novo pravilo.
1990-e — 2010-e: Statistički modeli (N-gram, HMM, Naive Bayes)
Umjesto ručnih pravila, modeli su počeli učiti statističke obrasce iz velikih skupova teksta (npr. "Ako prethodi riječ 'predsjednik', sljedeća je vjerovatno 'vlade' ili 'federacije'"). Ovi modeli su biti bolji, ali su imali kratku "memoriju" — mogli su gledati samo nekoliko prethodnih riječi.
2013-2017: Rekurentne neuronske mreže (RNN i LSTM)
Neuronske mreže koje procesiraju tekst sekvencijalno, riječ po riječ, pamteći "stanje" kroz skriveni vektor. LSTM (Long Short-Term Memory) je dodao mehanizme za dulje pamćenje. Ipak, imale su kritični problem.
2017: "Attention Is All You Need" — Transformer revolucija
Google Brain tim objavljuje naučni rad koji mijenja sve. Transformer arhitektura ne procesira tekst sekvencijalno, već paralelno, i koristi mehanizam "pažnje" (attention) za razumijevanje konteksta. GPT, BERT, Claude, Llama — svi su zasnovani na ovoj arhitekturi.
⚠️ Problem sa RNN/LSTM arhitekturom
Zbog sekvencijalnog procesiranja, RNN/LSTM su imali dva kritična problema:
1. Nemoguće paralelizovati: GPU-ovi su dizajnirani za masovni paralelizam. RNN mora čekati da procesira riječ N prije nego krene na riječ N+1, čime gubi dramatičnu prednost modernog hardvera.
2. Vanishing Gradient (Iščezavajući gradijent): Na dugim tekstovima (npr. ugovor od 10 stranica), matematički signal koji "nosi informaciju" o prvoj rečenici postaje toliko slab do kraja dokumenta da model praktično zaboravlja početak. Zamislite da čitate ugovor i da do 50. stranice potpuno zaboravite šta je pisalo na prvoj.
🔢 Fundamentalni Pojmovi: Skalari, Vektori, Matrice i Tenzori
Prije nego objasnimo Transformer, moramo definisati matematičke "objekte" sa kojima radi. Ovo su pojmovi koje ćete čuti u svakom razgovoru o AI-ju.
📐 Skalar (Scalar)
Najjednostavnija matematička veličina — jedan broj, bez smjera ni dimenzije. Primjeri: temperatura (36.6), cijena (42.50 KM), starost (25).
U AI kontekstu: Temperature parametar koji šaljete API-ju (0.7) je skalar.
📐 Vektor (Vector)
Uređeni niz skalara (brojeva). Možete ga zamisliti kao listu koordinata ili lista osobina.
Primjer iz geometrije: Tačka u 3D prostoru ima 3 koordinate: [x, y, z] = [10.5, -3.2, 7.0]
U AI kontekstu: Svaka riječ (token) je predstavljena vektorom od stotine ili hiljade brojeva, gdje svaki broj kodira jednu apstraktnu "dimenziju značenja". GPT-3 koristi vektore od 12,288 brojeva po tokenu!
Vektor za "Kralj": [0.2, -0.1, 0.9, 0.4, ..., 0.7] (12,288 elemenata)
📐 Matrica (Matrix)
2D niz brojeva — tabela redova i kolona. Ako imate 5 tokena, svaki predstavljen vektorom od 768 dimenzija, dobijate matricu 5×768.
U AI kontekstu: Attention matrica je ključna tabela koja pokazuje kako svaka riječ "pazi" na svaku drugu riječ u rečenici.
📐 Tenzor (Tensor) — Najvažniji pojam u AI!
Generalizacija skalara, vektora i matrica na N dimenzija. Ovo je često najneobičniji koncept početnicima, ali je zapravo vrlo logičan način organizacije podataka.
- Skalar = 0D (jedan broj, npr. jedan račun)
- Vektor = 1D niz (kolona iz tabele, npr. lista računa za danas)
- Matrica = 2D tabela (svi računi za cijeli mjesec posloženi po danima i tipovima)
- Tenzor rang 3 = 3D "kocka podataka" (arhiva tabela za sve mjesece u godini)
- Tenzor rang 4+ = arhive za sve godine, itd.
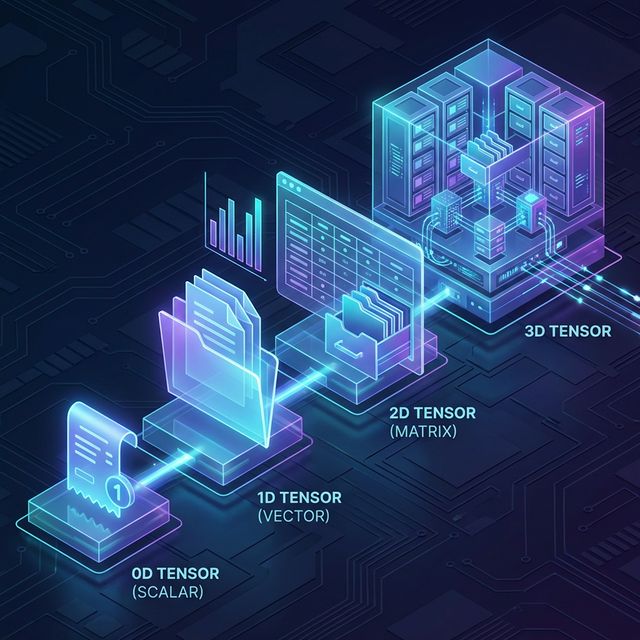
Od 1D papira, preko 2D ladice do 3D arhive.
Konkretno: Kada GPT procesira batch od 32 rečenica, svaka sa maksimalno 512 tokena, svaki token predstavljen vektorom od 768 dimenzija — radimo sa tenzorima dimenzija [32, 512, 768]. Ovo nema boljeg opisa osim "3D kocke podataka" koja živi u memoriji GPU-a. Veze između dimenzija omogućavaju modelu da "uči" kompleksne obrasce.
Zašto to zovemo "tenzori"? Naziv dolazi iz fizike (tenzori naprezanja u mehanici),
ali u ML kontekstu se koristi jer biblioteka PyTorch u Pythonu podatke čuva i obrađuje u strukturama
koje se zovu torch.Tensor.
Svaka operacija u neuronskoj mreži je zapravo matematička operacija nad ovim tenzorima.
💡 Analogija: Baza podataka i Tenzori
Zamislite relacionu bazu podataka. Jedno polje u tabeli (ID) je Skalar. Cijela kolona
"GodineStarosti" je Vektor. Kompletna tabela "Korisnici" sa više kolona i redova je Matrica. A šta
ako želimo analizirati snimke stanja te baze (backup) svaki dan kroz godinu dana? Dobijamo 3D Tenzor
sa indeksima: [Dan, Red, Kolona]. GPU-ovi su napravljeni upravo za brzo procesiranje
ovih masivnih arhiva brojeva paralelnim operacijama. Mreža ne procesira stvari kao ljudski "mozak"
čitajući i razmišljajući, već isključivo primjenjuje enormno mnogo matematičkih množenja preko ovih
tenzora.
🏗️ Anatomija Transformera
Transformer je tip neuronske mreže koji je Google Brain tim opisao u naučnom radu "Attention Is All You Need" (2017). Za razliku od RNN-ova koji čitaju tekst sekvencijalno, Transformer obrađuje sve tokene u tekstu istovremeno koristeći mehanizam self-attention.
Originalni Transformer ima dvije komponente:
- Enkoder (Encoder) — Prima ulazni tekst i gradi njegovo matematičko razumijevanje. Svaki token dobija kontekstualni vektor koji uzima u obzir sve ostale tokene. Primjer: BERT (Google) je samo-enkoder model. Odlično za: klasifikaciju teksta, sentiment analiza, odgovaranje na pitanja.
- Dekoder (Decoder) — Generuje output token po token, koristeći razumijevanje encodera i već generisane tokene. Primjer: GPT (OpenAI) i Llama (Meta) su samo-dekoder modeli. Odlično za: generisanje teksta, chatboti, code assistenti.
💡 Analogija: Prevođenje na strani jezik
Originalni Transformer bio je dizajniran za prevođenje. Enkoder čita englesku rečenicu i gradi njeno "razumijevanje" (kao čitanje i razmišljanje). Dekoder zatim generira bosansku rečenicu token po token (kao pisanje prijevoda). Moderni chatboti (GPT, Claude) su samo dekoderski dio odrasli na ogromnim skupovima podataka — oni ne trebaju enkoder jer generiše tekst direktno bez "pročitanog" izvora.
Unutrašnja Arhitektura — Korak po Korak
Sada ćemo proći kroz ono što se dešava kada pošaljete tekst LLM modelu. Svaki korak je posebna matematička transformacija unutar neuronske mreže.
Korak 1: Tokenizacija (Preprocessing)
Tekst se razbija na manje dijelove zvane tokeni. Token nije uvijek cijela riječ — može biti dio riječi, cijela riječ, ili čak interpunkcija. Svaki token dobija jedinstven ID broj iz rječnika modela.
"Firewall blokira zahtjev" → [7173, 5765, 24356, 8901]
(4 tokena, svaki je integer koji se referencira u lookup tabeli od stotinu hiljada mogućnosti)
Detaljno ćemo ovo obraditi u Lekciji 1.2.
Korak 2: Input Embeddings (Pretvaranje tokena u vektore)
Svaki token ID se pretražuje u ogromnoj lookup tabeli (Embedding Matrix) i pretvara u vektor (tenzor rang 1). Ova lookup tabela je naučena tokom treninga — nijanse značenja su ugrađene u relacije između vektora.
Ključna osobina: Matematički, slične riječi imaju slične vektore. Čuveni primjer: vektor("Kralj") - vektor("Muškarac") + vektor("Žena") ≈ vektor("Kraljica"). Ovo je jer su model vidio te riječi u sličnim kontekstima tokom treninga.
Dimenzije: GPT-2 small koristi 768-dimenzionalne vektore. GPT-3 koristi 12,288-dimenzionalne. Llama 3 8B koristi 4,096. Više dimenzija = više kapaciteta za nijansiranje značenja = veći model.
Korak 3: Positional Encoding
Transformer čita sve tokene paralelno (istovremeno), pa nema ugrađen pojam "redoslijeda" kao RNN koji čita sekvencijalno. Rečenice "Pas ujeda čovjeka" i "Čovjek ujeda psa" imaju iste tokene — ali sada ne bismo znali ko je grizeač, a ko žrtva!
Rješenje: Svakom embedding vektoru dodamo poseban "pozicijski" vektor koji kodira poziciju tokena u rečenici. Originalni rad koristi sinusoidalne funkcije:
PE(pos, 2i+1) = cos(pos / 10000(2i/d_model))
Gdje je pos pozicija tokena (0, 1, 2, ...), i dimenzija vektora,
i d_model ukupna dimenzionalnost. Noviji modeli (GPT-4, Llama 3) koriste moderniji
pristup
zvani RoPE (Rotary Position Embedding) koji bolje generalizuje na duže sekvence,
ali princip je isti: model mora znati gdje u rečenici se nalazi svaki token.
Korak 4: Self-Attention (Srce Transformera)
Ovo je najinovativniji i najvažniji dio. Pogledamo ga u sljedećoj sekciji detaljno.
Korak 5: Feed-Forward Neural Network (po tokenu)
Nakon attention mehanizma (koji "miješa" informacije između tokena), svaki token prolazi kroz kompletno odvojen Feed-Forward sloj — klasičnu neuronsku mrežu sa dva sloja i ReLU aktivacijom. Ovaj sloj "probavlja" i transformiše informaciju sakupljenu kroz attention.
Dimenzije: GPT-2 small ima dimenziju 768 (attention) → 3072 (FF unutrašnji sloj) → 768 (izlaz). Ovo proširivanje i skupljanje dimenzija daje modelu kapacitet za memorisanje i generalizaciju znanja.
Korak 6: Layer Normalization i Residual Connections
Kako mreža raste u dubinu (GPT-3 ima 96 slojeva!), treba je stabilizovati. Residual connection dodaje ulaz direktno na izlaz svakog sloja (zaobilazna putanja), čime sprječava "vanishing gradient" problem. Layer normalization normalizuje aktivacije na svaki sloj, ubrzavajući trening.
Korak 7: Output Layer i Softmax
Nakon svih slojeva, vektor zadnjeg (ili svakog, ovisno o zadatku) tokena prolazi kroz linearnu transformaciju i softmax funkciju koja ga pretvara u distribuciju vjerovatnoća po cijelom rječniku modela.
Token "Emina" → ... (96 slojeva) → vektor 12,288 dim →
Logits [12,288 → 50,257 rječnik]:
"je": 0.42, "radi": 0.18, "voli": 0.11, ...
Sljedeći token = uzorkovani iz ove distribucije
🎯 Self-Attention Mehanizam (Srce Transformera)
Ovo je najvažniji koncept u modernoj AI industriji. Razumijevanjem ovog mehanizma razumijete "zašto" LLM-ovi rade bolje od svega što je prethodilo.
Self-Attention dopušta modelu da za svaki token koji trenutno obrađuje "pogleda" sve ostale tokene u rečenici i odluči koliko su mu bitni (koliko im daje pažnje). Ovo radi paralelno za sve tokene istovremeno.
💡 Analogija: Soba stručnjaka
Zamislite da imate zadatak: odrediti šta tačno znači zamjenica "ona" u rečenici "Ana je pokrenula sistem, a potom ga je ona restartovala."

Stručnjaci ("Riječi") vijećaju o značenju riječi "Ona"
Vi pitate svakog stručnjaka u sobi ("Ana", "sistem", "restartovala") koliko misli da je relevantan za razumijevanje "one". "Ana" kaže: "Ja sam najrelevantnija! Ja sam imenica ženskog roda koja može vršiti radnju!" "sistem" kaže: "Manje sam relevantan, ja sam muški rod i više sam objekat." Ovi "glasovi" se sabiraju spram njihove težine i dobijena "ponderisana suma" (weighted sum) pomaže precizno razumjeti kontekst. Self-attention je upravo taj proces vijećanja stručnjaka formalizovan u mataričnu matematiku.
Query, Key, Value (Q, K, V) — Gledano kroz primjer "Ane"
Self-Attention koristi tri tenzora/matrice koje model uči kroz trening. Svaki ulazni token se multiplicira sa ove tri matrice i matematički "proizvodi" tri uloge za sebe (Q, K i V). Evo primjera logike za riječ "ona":
Ova formula radi sljedeće:
- Množimo Q i K matricu transonovano (Q · KT) — dobivamo "score" sličnosti između svakog para tokena
- Dijelimo s √d_k (kvadratnim korijenom dimenzije) da spriječimo prepotentno numerički stabilne vrijednosti
- Primjenjujemo softmax koji pretvara score-ove u distribuciju vjerovatnoća (sve se sabere na 1.0)
- Množimo s Value matricom V — "ponderirano skupljamo" vrijednosti na temelju attention score-ova
"Server nije mogao pokrenuti aplikaciju jer je bio {preopterećen}."
"Server nije mogao pokrenuti aplikaciju jer je bila {korumpirana}."
Sa Query-em za token "bio/bila":
- U prvoj rečenici: attention score za "Server" = 0.90 | "aplikaciju" = 0.05
→ "bio" se odnosi na Server (muški rod)
- U drugoj rečenici: attention score za "aplikaciju" = 0.89 | "Server" = 0.06
→ "bila" se odnosi na aplikaciju (ženski rod)
Model ovo nije naučen "gramatičkim pravilima" — naučio je
statistički, iz milijardi rečenica, koji kontekstualni obrasci
prepoznaju referencu zamjenice.Multi-Head Attention: Višestruka Perspektiva
Umjesto jedne kalkulacije pažnje, Transformer paralelno izračunava 12, 16, 96 (ovisno o modelu) odvojenih "głava" (heads) pažnje — each sa sa zasebnim Q, K, V matricama koja uče različite aspekte relacije:
- Głava 1 može tražiti gramatičke odnose (subjekat → predikat)
- Głava 2 može pratiti emociju ili ton rečenice
- Głava 3 može locirati imeničko-pridjevske veze
- Głava 4 može identificirati coreference (zamjenicu i imenicu)
- ... svaka głava spontano uči nešto korisno za predviđanje sljedećeg tokena
Na kraju, svi izlazi glava se konkateniraju i projiciraju natrag u dimenziju modela. GPT-3 ima 96 slojeva svaki sa 96 głava — to je 9,216 odvojenih "fokusiranih perspektiva" u jednom forward pass-u!
✅ Provjera Razumijevanja — Checkpoint 1
-
Pitanje: Šta bi se desilo da API-u pošaljete samo listu sirovih riječi
("vatrozid", "blokira") umjesto Tenzora sa Token ID-jevima?
Odgovor: Model (neuronska mreža) obrađuje samo matematiku. Da tekst nije prošao kroz Tokenizaciju i Embedding strukturu u Vektore (Tenzor), model mreže bi vratio grešku i krahirao. Ne "razumije" slova. -
Pitanje: Zašto koristimo Transformer (Attention) arhitekturu, a ne stare RNN
botove za obimne ugovore od 10 stranica?
Odgovor: RNN uzastopno čita riječ po riječ i gubi fokus na početak ugovora (Vanishing Gradient), jer se previše matematičkog sjećanja "razrijedi" do tog trenutka. Transformer pretražuje sve riječi paralelno formom Attentiona! -
Pitanje: Ako riječ kreira "oglas" o tome "koje osobine ona posjeduje za druge",
o kojoj matrici mehanizma pažnje (Attention) je kod?
Odgovor: O Key (K) matrici. Model koristi taj "oglas" (K) kako bi ostale poslane tokene upratio s Query (Q) "pitanjima" koja dolaze.
LAB O1: Vizualizacija Attention Mehanizma (BertViz)
U ovom labu ćemo isprogramirati Python skriptu koja učitava GPT-2 model lokalno, i
koristi BertViz biblioteku kako bi grafički prikazala kako neuronska mreža
uspostavlja odnose između riječi. Ovo je direktan vizualni prikaz attention matrica o kojima smo
upravo učili.
Provjera Python instalacije
Otvorite PowerShell (Windows dugme → kucajte "PowerShell" → Enter) i provjerite imate li Python instaliran:
# Provjera Python verzije (trebate 3.9, 3.10 ili 3.11)
python --version
# Ako dobijete "Python 3.10.x" ili slično - OK.
# Ako ne prepoznaje python, probajte:
python3 --version
# Provjera pip (Python package manager)
pip --versionAko Python nije instaliran: Idite na python.org/downloads, preuzmite Python 3.11 za Windows, tokom instalacije obavezno odaberite checkmark "Add Python to PATH".
Kreiranje projeknog foldera i virtualnog okruženja
Virtualno okruženje (venv) je izolovani Python "sandox" koji čuva biblioteke odvojene od sistema. Odlična praksa — svaki projekt ima svoje biblioteke, bez konflikta verzija.
# 1. Kreirajte folder za ovaj kurs na Desktop-u
mkdir C:\Users\$env:USERNAME\Desktop\AI_Kurs
cd C:\Users\$env:USERNAME\Desktop\AI_Kurs
# 2. Kreirajte virtuelno okruženje nazvano "venv"
python -m venv venv
# Ovo kreira folder "venv" u vašem projektnom folderu
# 3. AKTIVIRAJTE virtualno okruženje (obavezno svaki put!)
.\venv\Scripts\Activate.ps1
# Znate da je aktivno kada vidite "(venv)" na početku prompt-a:
# (venv) PS C:\Users\...\AI_Kurs>
# Ako dobijete grešku o "Execution Policy", pokrenite:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# Zatim ponovo pokrenite Activate.ps1Instalacija biblioteka
Sada instaliramo sve potrebne pakete. Ovo može trajati 3-10 minuta jer PyTorch je velik paket (~200MB):
# Uvjerite se da je (venv) aktivan (vidljiv u promptu)!
# PyTorch - matematička jezgra za tenzore (CPU verzija, dovoljna za lab)
pip install torch --index-url https://download.pytorch.org/whl/cpu
# HuggingFace Transformers - biblioteka za učitavanje GPT, BERT i ostalih modela
pip install transformers
# BertViz - interaktivna vizualizacija attention matrica
pip install bertviz
# Jupyter Lab - browser okruženje za interaktivno kodiranje
pip install jupyterlab ipywidgets
# Provjera instlacije:
pip list
# U listi trebate vidjeti: torch, transformers, bertviz, jupyterlabPokretanje Jupyter Lab-a
BertViz vizualizacije zahtijevaju browser okruženje. Jupyter Lab je web aplikacija koja pokrenuta lokalno prikazuje interaktivne bilježnice (Notebooks) gdje možemo pisati i izvršavati Python kod ćelija po ćelija.
# Pokrenite Jupyter Lab iz projektnog foldera:
jupyter lab
# Ovo će:
# 1. Pokrenuti lokalni web server na portu 8888
# 2. Automatski otvoriti browser na adresi: http://localhost:8888
# 3. Prikazati file manager vašeg projektnog folderaU Jupyter Lab-u, kliknite na dugme "Python 3 (ipykernel)" pod "Launcher" tab-om. Ovo otvara novi Notebook. Svaki "Kopiraj" blok koda ispod idete u novu ćeliju (klik na "+" ili SHIFT+ENTER za izvršavanje i prelazak na sljedeću ćeliju).
Pisanje koda za vizualizaciju (ćelija po ćelija)
Koristimo GPT-2 model (najmanji, 117M parametara) jer se preuzima brzo (~500MB) i koristi potpuno identičnu GPT arhitekturu kao GPT-4 — samo sa mnogo manje parametara.
Ćelija 1 — import biblioteka:
# Uvozimo klase iz HuggingFace Transformers biblioteke
from transformers import AutoTokenizer, AutoModel
# BertViz pruža head_view funkciju za interaktivnu vizualizaciju
from bertviz import head_view
import torch # PyTorch - radimo sa tenzorimaIzvršite ćeliju: SHIFT+ENTER. Ako nema grešaka, pređite na sljedeću.
Ćelija 2 — učitavanje modela (prvi put preuzima ~500MB):
# Definišemo koji model koristimo
model_name = 'gpt2' # Najmanji GPT-2 model
# AutoTokenizer automatski preuzima tokenizer za zadani model
# Tokenizer zna kako pretvoriti tekst u token ID-eve
tokenizer = AutoTokenizer.from_pretrained(model_name)
# AutoModel preuzima arhitekturu GPT-2 sa nasumičnim ili pretreniranim težinama
# output_attentions=True govori modelu da vrati attention matrice (inače ih ne vraća radi uštede memoria)
model = AutoModel.from_pretrained(model_name, output_attentions=True)
# Postavljamo model u evaluation mode (ne treniramo, samo koristimo)
model.eval()
print(f"✅ Model učitan! Broj parametara: {sum(p.numel() for p in model.parameters()):,}")
# Trebate vidjeti: ~124,439,808 (124 miliona) parametara za GPT-2 small
Šta se dešava? HuggingFace preuzima model sa svog huba i kešira ga u
C:\Users\USERNAME\.cache\huggingface\. Sljedeći put se učitava instantno (offline).
Ćelija 3 — tokenizacija i attention ekstrakcija:
# Testna rečenica iz domene sistemske administracije
text = "The firewall blocked the IP address because it was malicious."
# Korak 1: Tokenizacija — pretvaramo string u tensore token ID-eva
# return_tensors='pt' = vrati PyTorch tenzor (a ne Python listu)
# add_special_tokens=True = dodaj [BOS] Beginning-of-Sequence token
inputs = tokenizer.encode_plus(
text,
return_tensors='pt', # pt = PyTorch format
add_special_tokens=True
)
#########################################
# ako ne prodje iznad kod, probati ovo
inputs = tokenizer(
text,
return_tensors='pt',
add_special_tokens=True
)
#########################################
input_ids = inputs['input_ids'] # Tenzor sa token ID-evima: [[50256, 464, 2046, ...]]
print("Token IDs:", input_ids)
print("Oblik tenzora (shape):", input_ids.shape) # [1, 11] = 1 rečenica, 11 tokena
# Konvertujemo ID-eve natrag u čitljive tokene (da vidimo proces tokenizacije):
tokens = tokenizer.convert_ids_to_tokens(input_ids[0].tolist())
print("\nTokeni:", tokens)
# Primit ćete listu poput: ['The', 'Ġfirewall', 'Ġblocked', 'Ġthe', 'ĠIP', ...]
# Ġ (G sa kružićem) = space ispred tokena (BPE konvencija)Ćelija 4 — Forward pass i ekstrakcija attention:
# torch.no_grad() = ne računamo gradijente (nije trening, štedimo memoriju)
with torch.no_grad():
# Prosljeđujemo input_ids tenzor kroz sve slojeve GPT-2 modela
outputs = model(input_ids)
# outputs je tuple. Zadnji element je lista attention tenzora (1 per layer)
# GPT-2 small ima 12 slojeva, svaki vraća attention matricu
attention = outputs[-1] # Lista od 12 tenzora, svaki oblika [1, 12_heads, seq_len, seq_len]
print(f"Broj slojeva: {len(attention)}") # 12 za GPT-2 small
print(f"Oblik attention tenzora (1. sloj): {attention[0].shape}")
# [1, 12, 11, 11] = 1 batch × 12 głava × 11 tokena × 11 tokena
# Ovo je ono o čemu smo pričali teorijski! 11×11 matrica "ko gleda koga" po svakoj głaviĆelija 5 — Interaktivna vizualizacija:
# BertViz head_view prikazuje sve głave za sve slojeve interaktivno
# tokens = lista tagova za osi vizualizacije
head_view(attention, tokens)Analiza vizualizacije — Šta gledamo?
- Interaktivni grafik prikazuje tokenizirane riječi s lijeve i desne strane. Svaka "głava" je odvojen kvadrat.
- Zadržite miša (hover) iznad tokena "it" s lijeve strane. Pratite linije koje se iscrtavaju!
- Najdeblja linija od "it" treba voditi ka "IP" i "address". Mreža je shvatila da "it" referiše na IP adresu, a ne na firewall, iako "it" samo po sebi nema kontekst.
- Kliknite na dugmiće "heads" da vidite koje głave se specijalizuju na što. Neke całe głave prate sintaksne odnose (subjekat → objekat), druge se fokusiraju na semantičke relacije (uzrok → posljedica).
- Zaključak: Ovo se desilo jer je trening modela postavio milione Q i K matrica (parametara) koji detektuju ovakve coreference relacije u engleskom jeziku — bez ijednog eksplicitnog pravila programiranog od strane čovjeka.
Bonus: Numerički pregled attention score-ova
Da vidimo i "sirove" attention score-ove kao Python podatke:
import numpy as np
# Uzimamo attention iz prvog sloja, prve głave
# Oblik: [1, 12, seq_len, seq_len]
layer_0_head_0 = attention[0][0, 0, :, :].numpy() # Konvertujemo tenzor u numpy array
# Pronalazimo indeks tokena "it"
it_idx = tokens.index('Ġit') if 'Ġit' in tokens else -1
if it_idx >= 0:
print(f"\nAttention score-ovi za token 'it' (la głava 0, sloj 0):")
for i, (tok, score) in enumerate(zip(tokens, layer_0_head_0[it_idx])):
bar = "█" * int(score * 30) # Vizualni bar
print(f" {tok:20s} | {score:.4f} | {bar}")
print("\n💡 Zapamtite: ovo je samo 1 od 144 (12 slojeva × 12 głava) attention pattern-a!")✅ Zaključak i Sljedeći Koraci
U ovoj lekciji smo objasnili temelje: šta su skalari, vektori, matrice i tenzori (matematički objekti kojim barata svaka AI biblioteka). Zatim smo prošli kroz arhitekturu Transformera korak po korak — Embed → Positional Encode → Multi-Head Attention → Feed-Forward → Output.
Kroz BertViz lab, vidjeli smo vizualno kako attention matrice "uče" da prate relacije između riječi bez ijednog eksplicitnog pravila. Ovo je temelj razumijevanja zašto GPT-4 može odgovoriti na kompleksna pitanja bolje od bilo kojeg sistema koji mu je prethodio.
U sljedećoj lekciji (11:15h) ulazimo dublje u Tokenizaciju — kako model tačno lomi tekst na tokene, zašto bosanski jezik "košta više" od engleskog, i kako upravljati Context Window limitima.