🎲 Matematika Iza Svakog Odgovora LLM-a
LLM-ovi (GPT, Claude, Llama) nisu baze podataka koje pretražuju internet za tačnim odgovorom. Oni su probabilistički generatori slijednog tokena — za svaki novi token koji generišu, računaju distribuciju vjerovatnoća po cijelom rječniku (npr. 100,000 mogućih tokena), a zatim biraju sljedeći token na osnovu te distribucije.
📌 Šta su "Logits" i "Softmax"?
Logits su "sirovi" numerički izlazi zadnjeg sloja neuronske mreže — vektor od N vrijednosti (gdje N = veličina rječnika). Ove vrijednosti nisu vjerovatnoće, mogu biti negativne ili jako velike.
Softmax je matematička funkcija koja konvertuje logits u pravu distribuciju vjerovatnoća (sve se saberu na 1.0, sve su između 0 i 1):
softmax(z_i) = exp(z_i) / Σ exp(z_j) [za sve j u rječniku]
Konkretno: Za nastavak rečenice "Vatrozid je..." — Model izračunava: "blokirao": 42%, "aktivan": 21%, "isključen": 15%, "onemogućio": 8%, ... itd. Koji token će biti sljedeći? Zavisi od sampling strategije (parametara koje vi podešavate)!
💡 Analogija: Autocomplete sa predrasudama
Zamislite telefon autocomplete koji sugerira sljedeću riječ. Kada pišete "Hvala na" — on predlaže "odgovoru" (60%), "pomoći" (25%), "pozivu" (10%), ostalo (5%). Normalno autocomplete bira prvu (deterministički). GPT-ov sampling može odabrati drugu ili treću — upravo ova "fleksibilnost" čini odgovore raznovrsnim, ali i potencijalno "pogrešnim". Temperatura parametar kontroliše koliko je model "smion" u ovom odabiru.
🎚️ Kontrolni Hiperparametri API-ja
Kada šaljete zahtjev LLM serveru (OpenAI API, Azure OpenAI, Anthropic Claude API, lokalni Ollama), uz tekst šaljete i JSON objekt s parametrima. Ovi parametri matematički modificiraju način na koji model bira sljedeći token. Razumijevanje ovih parametara je ključna vještina arhitekte koji gradi AI sisteme.
Šta radi: Dijeli sve logit vrijednosti s ovim brojem prije softmax-a. Nizak temp → model "jakim glasom" naglašava tokene visoke vjerovatnoće (deterministo). Visok temp → "izravnava" distribuciju, daje šansu rijetkim tokenima (kreativno/halucinacije).
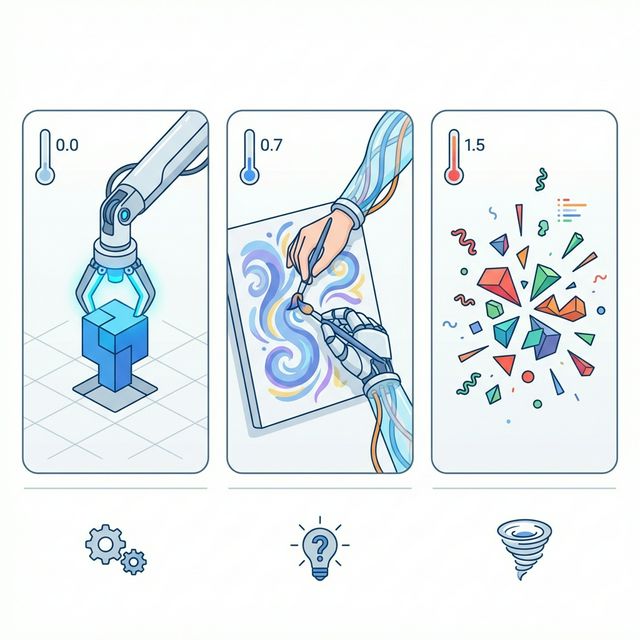
Od predefinisane robotske preciznosti (Temp=0) do nepredvidivog kreativnog haosa (Temp=1.5).
Strog
Halucinacije
- 0.0 – Ekstrakcija podataka, JSON parsing, klasifikacija, SQL generisanje
- 0.2 – Pisanje koda, dokumentacija, faktualni odgovori
- 0.7 – Chatboti, pisanje emailova, blog postovi
- 1.0+ – Brainstorming, kreativni tekstovi
- 1.5+ – Eksperimentisanje (oprez: halucinacije, gublene logike)
Šta radi: Umjesto da razmatra sve moguće tokene, model sortira tokene po vjerovatnoći i uzima samo najvjerovatnije dok njihova zbirna vjerovatnoća ne dostigne P. Ostatak tokena ima vjerovatnoću 0.
Primjer: top_p=0.9 → Model razmatra samo tokene čija zbirna vjerovatnoća = 90%. Ako prvih 5 tokena pokriva 90% — ostali se ignorišu, čak i ako ih ima 99,995.
⚠️ Zlatno pravilo: Koristite SAMO temperature ILI SAMO top-p, nikada oboje podešene istovremeno. OpenAI i Anthropic dokumentacija to eksplicitno preporučuju jer kombinovani efekti nisu predvidivi.
Šta radi: Tvrdi limit broja tokena koje model može generisati u odgovoru. Model prestaje čim dostigne ovaj broj, čak i usred rečenice.
Zašto je ovo krucijalno? Output tokeni su 3× skuplji od input tokena (GPT-4o: $5/1M input vs $15/1M output). Bez ovog limita, verbose modeli mogu generisati puno više teksta nego što je potrebno, troše budget i uspore API.
- 50-100 – Kratki odgovori, klasifikacija, DA/NE
- 256-512 – Standardni chatbot odgovori
- 1000-2000 – Dokumentacija, duge analize
Šta radi: Penalizuje model koji koristi istu lekseičku oznaku. Svaki put kada je token korišten ranije u odgovoru, njegova vjerovatnoća pri ponovnom biranju se smanjuje za frequency_penalty × broj_pojavljivanja.
Praktično: Visoka vrijednost (npr. 0.8) tjera model da koristi raznovrsniji rječnik i izbjegava ponavljanje. Korisno za kreativne tekstove ili izvještaje.
Šta radi: Za svaki token koji se pojavio bar jednom ranije u odgovoru, primijeniti konstantnu penalizaciju (ne zavisi od broja pojavljivanja). Razlika od frequency penalty: ovaj tjera na nove teme, onaj na novi rječnik.
Praktično: Korisno kad chatbot u dugim razgovorima počne kružiti oko iste teme. Visoki presence_penalty ga gura da uvodi nove aspekte razgovora.
Šta radi: Lista stringova na kojima model prestaje generisanje, čak i ako nije dostigao max_tokens. Model NE vraća ove stringove u odgovoru.
Zlatni primjer upotrebe: Kada tražite od modela da generiše Python kod i ne želite da ide dalje od funkcije:
stop: ["# END", "```", "\ndef "]
📡 Problem Latencije: Streaming API (SSE)
Veliki LLM-ovi (GPT-4, Claude 3.5) generišu otprilike 30-60 tokena u sekundi
za API pozive (zavisi od opterećenja servera). Ako tražimo odgovor od 1000 tokena —
bez ikakvog trika moramo čekati: 1000 / 40 = ~25 sekundi dok ne dobijemo
complete JSON odgovor.
Ovo je neprihvatljivo za korisničko iskustvo. Rješenje koje svi moderni AI interfejsi koriste:
🌊 Server-Sent Events (SSE) i Streaming Mode
Parametar "stream": true u JSON zahtjevu govori serveru da
umjesto da pričeka kompletni odgovor, pušta (stream-a) djeliće teksta
(delta) čim ih neuronska mreža generira.
Umjesto HTTP response-a koji stiže odjednom, klijent prima niz kratkih HTTP "komadića" (chunks) u formatu Server-Sent Events — otvorena HTTP veza koja prima "event: data: ..." tekstualne poruke.
Iz perspektive korisnika: Iste onako kako pišete SMS — slova se pojavljuju jedno po jedno, chatbot "piše" u real-time. Ovo smanjuje percipiranu latenciju sa 25 sekundi na "instant" — korisnik vidi prve tokene za < 1 sekundu.
Detaljna implementacija streaming-a u React, Blazor i Vanilla JS — radimo u Modulu 8 (Semantic Kernel).
🛡️ Sigurnost API Ključeva — Apsolutno Pravilo
API ključ (koji plaćate OpenAI-ju ili Anthropic-u) je kao kreditna kartica. Ako ga izgubite ili javno objavite (npr. na GitHub-u), bots automatski skeniraju javne repozitorije i mogu potrošiti hiljade dolara u satima.
- Nikada ne hardkodirajte ključeve u Python kod (
api_key = "sk-...") - Koristite .env fajlove i
python-dotenvbiblioteku - Dodajte
.envu.gitignorefajl odmah pri kreiranju projekta - Koristite environment varijable u Docker/Kubernetes deployment-u
- Redovno rotajte ključeve (generirajte nove, stare obrisite) u OpenAI dashboard-u
LAB O3: Anatomija HTTP POST Zahtjeva i Efekti Temperature
U ovom labu gradimo Python skriptu koja direktno komunicira sa OpenAI API-jem bez SDK-a
(koristeći samo requests biblioteku) da vidimo tačnu strukturu HTTP zahtjeva.
Zatim eksperimentišemo sa temperature parametrom.
⚠️ Ovaj lab zahtijeva OpenAI API ključ. Ako nemate pristup, lab možete pratiti kao demonstraciju predavača ili koristiti lokalni Ollama API (isti format — mijenjate samo URL i model ime). Instrukcija za lokalni Ollama API je na kraju laba.
Struktura ChatGPT / Claude Message Formata
Svi modererni LLM API-jevi (OpenAI, Anthropic, Ollama, Azure OpenAI) koriste standardni
Chat Completion format — JSON objekat s listom poruka, svaka ima role
i content:
{
"model": "gpt-4o",
"temperature": 0.0,
"max_tokens": 500,
"messages": [
{
"role": "system",
"content": "Ti si inženjerski alat za dijagnostiku sistema. Odgovaraj isključivo na bosanskom jeziku. Budi precizan i koncizan."
},
{
"role": "user",
"content": "Prikazujem Out Of Memory grešku na Docker kontejnerima svako jutro u 3:00. Koji su najčešći uzroci?"
}
]
}
/*
OBJAŠNJENJE ULOGA:
- "system": Definiše identitet i ponašanje AI-ja. Čita se jednom na početku.
Analogija: Job description za zaposlenika.
- "user": Poruka od korisnika aplikacije (input).
- "assistant": Historija prošlih odgovora modela (za multi-turn konverzacije).
Vi ovo šaljete ručno u svakom pozivu — server je "stateless"!
*/Kreiranje .env fajla
U root folderu projekta (AI_Kurs), napravite fajl tačno imenovan .env
(bez ekstenzije). Koristite Notepad ili VS Code. Unesite ključeve koje ste dobili:
OPENAI_API_KEY=sk-proj-OVDJE_UNESITE_VAŠ_KLJUČ
# Ako nemate ključ, ostavite ovako i koristite lokalni Ollama na kraju labaSada kreirajte .gitignore fajl da zaštitite ključ:
# Kreiranje .gitignore fajla koji sprječava Git da prati .env
echo ".env" | Out-File -FilePath .gitignore -Encoding utf8
echo "venv/" | Out-File -FilePath .gitignore -Encoding utf8 -Append
echo "__pycache__/" | Out-File -FilePath .gitignore -Encoding utf8 -Append
echo "*.pyc" | Out-File -FilePath .gitignore -Encoding utf8 -Append
# Instalacija python-dotenv za čitanje .env fajlova
pip install python-dotenv requestsPython skripta za direktni API poziv (api_test.py)
Napravite fajl api_test.py u VS Code i unesite sljedeći kod:
"""
api_test.py - Direktni HTTP poziv OpenAI API-ju (bez SDK)
Cilj: Vidjeti tačnu strukturu request/response i testirati temperature parametar
"""
import os
import json
import requests
from dotenv import load_dotenv
# Korak 1: Učitavanje API ključa iz .env fajla
# load_dotenv() čita .env fajl i postavlja varijable u os.environ
load_dotenv()
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
print("❌ OPENAI_API_KEY nije pronađen u .env fajlu!")
print(" Kreirajte .env fajl sa: OPENAI_API_KEY=sk-...")
exit(1)
print(f"✅ API ključ pronađen: ...{api_key[-8:]}") # Prikazujemo samo zadnjih 8 znakova
# Korak 2: Definisanje API endpoint-a
# OpenAI-jeva Chat Completion API ruta
url = "https://api.openai.com/v1/chat/completions"
# Korak 3: HTTP Headers (Authorization + Content-Type)
headers = {
"Content-Type": "application/json", # Govorimo serveru format podataka
"Authorization": f"Bearer {api_key}" # Bearer token autentikacija
}
# Korak 4: Definisanje system prompta i user poruke
SYSTEM_PROMPT = """You are a senior DevOps engineer and Linux system administrator.
Provide concise, actionable answers. Always include relevant commands.
Respond in Bosnian language."""
USER_QUESTION = "Objasnite šta je OOM Killer u Linux kernelu i kako spriječiti Out-of-Memory greške na produkcijskim serverima."
print(f"\n📤 Pitanje: {USER_QUESTION}")
print("="*70)
# Korak 5: Testiranje TEMPERATURE efekta
# Testiramo isti prompt sa različitim temperature vrijednostima
temperatures_to_test = [0.0, 0.7, 1.5]
for temp in temperatures_to_test:
print(f"\n🌡️ TEMPERATURE = {temp}")
print("-"*50)
# JSON tijelo zahtjeva
payload = {
"model": "gpt-4o",
"temperature": temp,
"max_tokens": 250, # Ograničavamo dužinu odgovora
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_QUESTION}
]
}
try:
# Slanje HTTP POST zahtjeva
response = requests.post(url, headers=headers, json=payload, timeout=30)
if response.status_code == 200:
data = response.json() # Parsiramo JSON odgovor
# Ekstrakcija teksta odgovora iz nested JSON strukture
answer = data['choices'][0]['message']['content']
finish_reason = data['choices'][0]['finish_reason'] # 'stop', 'length', itd.
# Token usage informacije (za praćenje troškova)
usage = data['usage']
print(f"Odgovor:\n{answer}")
print(f"\n📊 Token Statistike:")
print(f" Input: {usage['prompt_tokens']:,} tokena")
print(f" Output: {usage['completion_tokens']:,} tokena")
print(f" Total: {usage['total_tokens']:,} tokena")
print(f" Finish: {finish_reason}")
# Izračun troška za ovaj poziv
cost = (usage['prompt_tokens'] * 5.0 / 1_000_000) + \
(usage['completion_tokens'] * 15.0 / 1_000_000)
print(f" 💰 Trošak ovog poziva: ${cost:.6f}")
elif response.status_code == 401:
print("❌ Greška 401: Neispravan API ključ!")
elif response.status_code == 429:
print("❌ Greška 429: Rate limit dostignut. Pričekajte malo.")
else:
print(f"❌ Greška {response.status_code}: {response.text[:300]}")
except requests.exceptions.Timeout:
print("❌ Timeout: API poziv nije odgovoriti u 30 sekundi")
except requests.exceptions.ConnectionError:
print("❌ Greška konekcije: Nema internet veze")
print("\n" + "="*70)
print("✅ Test završen!")Pokretanje i analiza
python api_test.py-
Sa
temperature=0.0: Odgovor je precizan, tehnički ispravna lista uzroka. Ako pozovete skriptu 5 puta uz isti prompt — odgovori su gotovo identični. Ovo je idealno za ekstrakciju podataka, klasifikaciju, i sve gdje trebate ponovljivost. -
Sa
temperature=0.7: Odgovor je i dalje informativan nagli ali variranjem u formulaciji. Svaki poziv može dati nešto drugačiji stil objašnjenja. -
Sa
temperature=1.5: Primijetit ćete da model može unositi nepostojeće detalje, preskakati logiku ili miješati jezike. Halucinacije su učestalije. Na bosanskom jeziku (rijetkom u trening podacima) efekti su izražajniji. -
Zaključak za Arhitektu: Uvijek eksplicitno postavljajte
temperatureimax_tokensu produkcionom kodu. Nikad ne ostav ljajte na default — default ponašanje se može promijeniti između verzija API-ja bez upozorenja!
Alternativa: Lokalni Ollama API (bez OpenAI ključa)
Ollama izlaže OpenAI-kompatibilan REST API na lokalnom portu 11434. Ako imate Ollama instaliran s Llama 3.1 modelom (iz narednih lekcija), promijenite samo URL i model:
# Za Ollama lokalni API, zamjenite ove vrijednosti:
url = "http://localhost:11434/v1/chat/completions" # Lokalni Ollama
headers = {
"Content-Type": "application/json",
# Nema Authorization header-a za lokalni Ollama!
}
# U payload-u promjenite model:
payload["model"] = "llama3.1" # Ili koji god model imate instaliran
# Sve ostalo (temperature, max_tokens, messages) ostaje identično!
# Ovo je moćna prednost: OpenAI-compatible API format je de-facto standard✅ Checkpoint — Provjera Razumijevanja
-
Pitanje: Dobili smo zadatak da napravimo bota za klasifikaciju e-mailova
korisnika u direktorijume ("Dozvole", "Žalbe", "Upiti"). Koju temperaturu (od 0.0 do 1.5) trebamo
postaviti u API pozivu i zašto?
Odgovor: Temperature treba biti 0.0. Želimo visoku determinističnost — isti sadržaj e-maila uvijek treba rezultirati isključivo istom kategorijom. Ne želimo da bot tu "rezonira sa varijacinjama". -
Pitanje: Pokrenuli ste test sa API-jem, ali se generisani odgovor bot-a naglo
prekinuo usred rečenice bez tačke na kraju: "(...) te se obavezno obratite šalteru br". Šta je
presjeklo bot?
Odgovor: Skoro je sigurno da ste probili (došli do maksimuma) max_tokens broj u toku samog generisanja odgovora iz memorije. Model se automatski prestao generisati zbog praga zaštite budžeta. -
Pitanje: U web aplikaciju ste priključili OpenAI API, ali osjećate veliku
tromost UI-a jer korisnik svaki put čeka naslijepo 15-ak sekundi na cijeli printan tekst. Koji
mehanizam Vam fali u zahtjevu (i response handlerima UI-ja)?
Odgovor: Vaš API zahtjev nije omogućio Streaming Request ponašanje (SSE) parametrom"stream": truečime biste vidjeli ispis token po token bez latencije i zamrzavanja osjećaja na webu.
✅ Zaključak
Razumijemo matematiku kojom LLM generiše tekst (probabilistički sampling) i sve ključne parametre koji kontrolišu to ponašanje. Postavljanjem temperature=0.0 i eksplicitnim max_tokens limitom, možemo izgraditi predidljive, troškovnosvjesne produkcione AI sisteme.
U završnom workshop-u ovog dana (Modul 1.4) spajamo sve što smo naučili u multi-model Python Sandbox aplikaciju koja simultano komunicira sa OpenAI i Anthropic API-jevima.