📖 Šta su Baze Podataka?
Baza podataka je organizovana kolekcija podataka koja se čuva i pristupa elektronski. Zamislite je kao digitalni ormar za dokumente gdje se informacije čuvaju na strukturiran način koji olakšava pronalaženje, ažuriranje i upravljanje.

Ilustracija koncepta baze podataka kao sigurnog digitalnog trezora
Baze podataka rješavaju kritične probleme u razvoju softvera:
- Trajnost Podataka: Informacije preživljavaju restartovanje aplikacije i padove servera
- Integritet Podataka: Pravila osiguravaju da podaci ostaju tačni i konzistentni
- Istovremeni Pristup: Više korisnika može raditi sa podacima istovremeno
- Sigurnost: Kontrola ko može čitati, mijenjati ili brisati podatke
- Performanse: Optimizirani mehanizmi za skladištenje i dohvaćanje
💡 Sistem za Upravljanje Bazama Podataka (DBMS)
Sistem za Upravljanje Bazama Podataka (DBMS) je softver koji upravlja bazama podataka. SQL Server, MySQL, PostgreSQL su svi DBMS proizvodi. Oni pružaju alate i interfejse potrebne za kreiranje, održavanje i interakciju sa bazama podataka.
🗂️ Tipovi Baza Podataka
Baze podataka se mogu kategorisati na nekoliko načina. Razumijevanje ovih kategorija pomaže vam da odaberete pravu bazu podataka za vaše potrebe.
1. Relacijske Baze Podataka (SQL Baze)
Relacijske baze podataka čuvaju podatke u tabelama sa redovima i kolonama. Tabele su povezane jedna sa drugom kroz strane ključeve (foreign keys), stvarajući strukturirani, normalizovani model podataka.
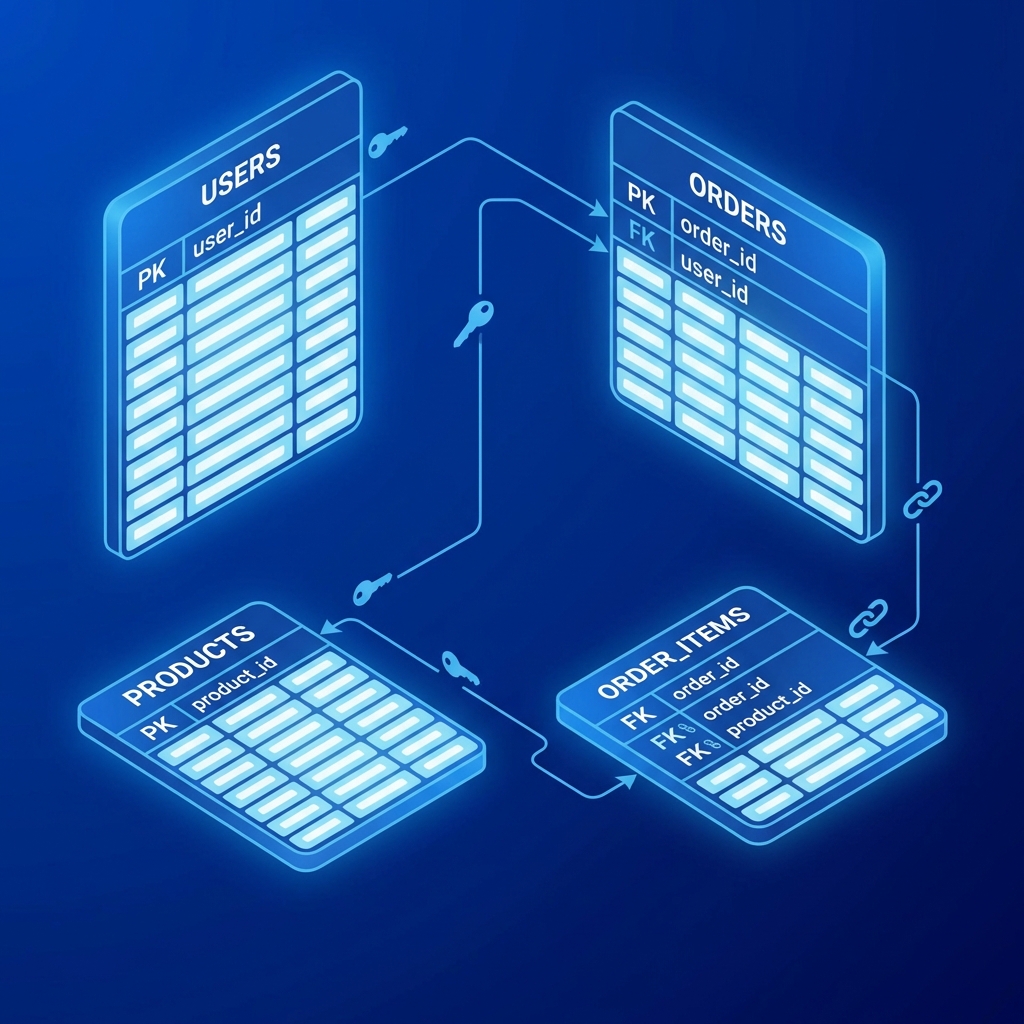
Vizualizacija relacijske strukture sa tabelama i ključevima
-- Primjer: Odnos između Zaposlenika, Odjeljenja i Projekata
CREATE TABLE Stats.Employees (
EmployeeID INT PRIMARY KEY IDENTITY(1,1),
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
JMBG NVARCHAR(13) NOT NULL UNIQUE,
DepartmentID INT NOT NULL,
Position NVARCHAR(100) NOT NULL,
Salary DECIMAL(10,2) NOT NULL,
HireDate DATE NOT NULL
);
CREATE TABLE Stats.Departments (
DepartmentID INT PRIMARY KEY IDENTITY(1,1),
DepartmentName NVARCHAR(100) NOT NULL,
DepartmentCode NVARCHAR(20) NOT NULL UNIQUE,
Budget DECIMAL(15,2) NOT NULL
);
CREATE TABLE Stats.Projects (
ProjectID INT PRIMARY KEY IDENTITY(1,1),
ProjectName NVARCHAR(200) NOT NULL,
DepartmentID INT NOT NULL,
Budget DECIMAL(15,2) NOT NULL,
StartDate DATE NOT NULL,
Status NVARCHAR(50) NOT NULL,
CONSTRAINT FK_Projects_Departments
FOREIGN KEY (DepartmentID)
REFERENCES Stats.Departments(DepartmentID)
);
Ključne Karakteristike:
- Strukturirani podaci sa unaprijed definisanim shemom
- ACID svojstva (Atomicity, Consistency, Isolation, Durability)
- SQL (Structured Query Language) za upite
- Jaka integritet podataka kroz ograničenja
- Najbolje za: Transakcione sisteme, finansijske podatke, strukturirane poslovne podatke
ACID Svojstva - Detaljno Objašnjenje
ACID je akronim koji predstavlja četiri ključna svojstva koja osiguravaju pouzdanost transakcija u relacijskim bazama podataka. Ova svojstva garantuju da transakcije budu pouzdane i konzistentne čak i u slučaju grešaka ili padova sistema.
🔒 Atomicity (Atomičnost)
Atomičnost garantuje da se transakcija izvršava u cijelosti ili se uopće ne izvršava. Ako bilo koji dio transakcije ne uspije, cijela transakcija se poništava (rollback).
Primjer:
- Transfer novca sa jednog računa na drugi mora uključivati i oduzimanje sa jednog i dodavanje na drugi račun
- Ako bilo koji korak ne uspije, oba se moraju poništiti
- Nema mogućnosti "poluizvršene" transakcije
✅ Consistency (Konzistentnost)
Konzistentnost osigurava da transakcija prenese bazu podataka iz jednog valjanog stanja u drugo. Sve pravila integriteta, ograničenja i validacije moraju biti zadovoljene.
Primjer:
- Primarni ključ mora biti jedinstven - ne može postojati duplikat
- Foreign key mora referencirati postojeći red u drugoj tabeli
- Provjere ograničenja (CHECK constraints) moraju biti zadovoljene
🔐 Isolation (Izolacija)
Izolacija osigurava da istovremene transakcije ne interferiraju jedna sa drugom. Svaka transakcija vidi konzistentan snapshot podataka, čak i ako se druge transakcije izvršavaju istovremeno.
Primjer:
- Dvije transakcije koje čitaju isti podatak neće vidjeti nepotpune izmjene druge transakcije
- Transakcija koja ažurira podatke neće vidjeti izmjene druge transakcije dok se ne završi
- Različiti nivoi izolacije (Read Uncommitted, Read Committed, Repeatable Read, Serializable) kontrolišu ovu izolaciju
💾 Durability (Trajnost)
Trajnost garantuje da jednom kada je transakcija potvrđena (committed), izmjene će biti trajne čak i u slučaju pada sistema, greške u napajanju, ili drugih problema.
Primjer:
- Nakon što se transakcija potvrdi, podaci se pišu na disk
- Transaction log čuva zapis svih izmjena
- Nakon pada sistema, baza podataka se može vratiti u poslednje konzistentno stanje koristeći log
-- Primjer transakcije koja demonstrira ACID svojstva
-- Transfer budžeta između projekata unutar istog odjeljenja
BEGIN TRANSACTION;
-- Atomicity: Ova transakcija mora biti cijela ili ništa
UPDATE Stats.Projects SET Budget = Budget - 100000 WHERE ProjectID = 1;
UPDATE Stats.Projects SET Budget = Budget + 100000 WHERE ProjectID = 2;
-- Consistency: Provjera da li je budžet projekta u validnom stanju
IF (SELECT Budget FROM Stats.Projects WHERE ProjectID = 1) < 0
BEGIN
-- Ako je provjera neuspješna, rollback (Atomicity)
ROLLBACK TRANSACTION;
PRINT 'Transakcija poništena: Nedovoljno budžeta u projektu';
END
ELSE
BEGIN
-- Isolation: Druge transakcije neće vidjeti ove izmjene dok se ne commit-uje
-- Durability: Nakon commit-a, izmjene su trajne
COMMIT TRANSACTION;
PRINT 'Transakcija uspješna: Budžet prebačen između projekata';
END
GOSQL (Structured Query Language) - Prošireno Objašnjenje
SQL (Structured Query Language) je standardizovani programski jezik dizajniran za upravljanje relacijskim bazama podataka. SQL omogućava kreiranje, čitanje, ažuriranje i brisanje podataka, kao i upravljanje strukturom baze podataka.
📚 SQL Kategorije Komandi
SQL komande se dijele u nekoliko kategorija:
- DDL (Data Definition Language): Kreiranje i modifikacija strukture baze
podataka
CREATE- Kreiranje tabela, baza, indeksaALTER- Modifikacija postojećih objekataDROP- Brisanje objekata
- DML (Data Manipulation Language): Manipulacija podacima
SELECT- Čitanje podatakaINSERT- Dodavanje novih podatakaUPDATE- Ažuriranje postojećih podatakaDELETE- Brisanje podataka
- DCL (Data Control Language): Kontrola pristupa
GRANT- Dodeljivanje dozvolaREVOKE- Oduzimanje dozvola
- TCL (Transaction Control Language): Upravljanje transakcijama
COMMIT- Potvrđivanje transakcijeROLLBACK- Poništavanje transakcijeSAVEPOINT- Kreiranje tačke za vraćanje
-- DDL: Kreiranje tabele
CREATE TABLE Stats.EconomicData (
DataID INT PRIMARY KEY IDENTITY(1,1),
RegionID INT NOT NULL,
Year INT NOT NULL CHECK (Year >= 2000 AND Year <= 2100),
GDP DECIMAL(18,2) CHECK (GDP >= 0),
UnemploymentRate DECIMAL(5,2) CHECK (UnemploymentRate >= 0 AND UnemploymentRate <= 100),
CONSTRAINT FK_EconomicData_Regions
FOREIGN KEY (RegionID)
REFERENCES Stats.Regions(RegionID)
);
-- DML: Dodavanje podataka
INSERT INTO Stats.EconomicData (RegionID, Year, GDP, UnemploymentRate)
VALUES (1, 2023, 10500000000.00, 15.5);
-- DML: Čitanje podataka
SELECT r.RegionName, ed.Year, ed.GDP, ed.UnemploymentRate
FROM Stats.EconomicData ed
INNER JOIN Stats.Regions r ON ed.RegionID = r.RegionID
WHERE ed.Year = 2023
ORDER BY ed.GDP DESC;
-- DML: Ažuriranje podataka
UPDATE Stats.EconomicData
SET UnemploymentRate = UnemploymentRate - 0.5
WHERE Year = 2023 AND RegionID = 1;
-- DML: Brisanje podataka
DELETE FROM Stats.EconomicData
WHERE DataID = 5;
-- TCL: Transakcija - Transfer budžeta između projekata
BEGIN TRANSACTION;
UPDATE Stats.Projects SET Budget = Budget - 100000 WHERE ProjectID = 1;
UPDATE Stats.Projects SET Budget = Budget + 100000 WHERE ProjectID = 2;
COMMIT TRANSACTION;Popularne Relacijske Baze Podataka:
- SQL Server (Microsoft) - Enterprise nivo, Windows/Linux
- MySQL - Open source, široko korišten za web aplikacije
- PostgreSQL - Napredna open source baza podataka
- Oracle - Enterprise baza podataka, visoke performanse
- MariaDB - MySQL fork, vođen zajednicom
2. NoSQL Baze Podataka
NoSQL (Not Only SQL) baze podataka pružaju fleksibilne modele podataka koji ne zahtijevaju fiksnu shemu. Dizajnirane su za skalabilnost i performanse sa velikim količinama podataka.
NoSQL Kategorije:
- Document Databases: Čuvaju podatke kao dokumente (JSON/BSON)
- Key-Value Stores: Jednostavni parovi ključ-vrijednost (Redis, DynamoDB)
- Column-Family Stores: Čuvaju podatke u kolonama (Cassandra, HBase)
- Graph Databases: Čuvaju relacije kao grafove (Neo4j, ArangoDB)
🔑 Kada Koristiti SQL vs NoSQL?
Koristite SQL (Relacijski): Kada vam trebaju ACID transakcije, složeni upiti, integritet podataka, i strukturirani podaci sa relacijama.
Koristite NoSQL: Kada vam treba horizontalno skaliranje, fleksibilne sheme, visok write throughput, ili specifični modeli podataka (dokumenti, grafovi).
🧠 Vektorske Baze Podataka: AI Revolucija
Vektorske baze podataka su specijalizovane baze podataka dizajnirane za skladištenje i pretraživanje visoko-dimenzionalnih vektora (nizovi brojeva). One su esencijalne za AI aplikacije, posebno u semantic search, preporučnim sistemima, i aplikacijama sa large language model (LLM).

Futuristički prikaz vektorskih embeddingsa i AI konekcija

Semantic Search: Razumijevanje namjere iza ključnih riječi (npr. "Delicious Food" pronalazi picu i suši)
🏗️ Moderna Softverska Arhitektura
U modernom razvoju softvera, rijetko se oslanjamo samo na jedan tip baze podataka. Praksa poznata kao Polyglot Persistence podrazumijeva korištenje različitih tehnologija za skladištenje podataka kako bi se iskoristile prednosti svake.

Dijagram moderne arhitekture sa integrisanim različitim tipovima baza
🎯 Uloga Svake Komponente
U ovom ekosistemu, svaki element ima specifičnu ulogu:
- SQL Server (Relacijska Baza): Čuva kritične transakcijske podatke (korisnici, narudžbe, plaćanja). Osigurava ACID integritet.
- Redis (In-Memory / Key-Value): Služi za keširanje (caching) i upravljanje sesijama. Osigurava ekstremno brz pristup podacima.
- Vektorska Baza (Vector DB): Čuva embeddings za AI funkcionalnosti, pretraživanje sličnosti i semantičku pretragu.
- Document DB (NoSQL): Čuva fleksibilne, nestrukturirane podatke poput logova, konfiguracija ili dinamičkih profila.
Kako Vektorske Baze Rade sa LLM (Large Language Models)
Vektorske baze podataka su kritična komponenta u modernim LLM aplikacijama. Evo kako funkcionišu zajedno:
🔄 LLM i Vektorske Baze - Integracija
- Generisanje Embeddings:
- LLM modeli (kao što su GPT-4, Claude, ili lokalni modeli) imaju ugrađene embedding modele
- Tekst se konvertuje u vektore pomoću embedding modela (npr. OpenAI ada-002, text-embedding-3)
- Svaki dokument ili upit postaje vektor sa stotinama ili hiljadama dimenzija
- Skladištenje u Vektorskoj Bazi:
- Vektori dokumenata se čuvaju u vektorskoj bazi podataka
- Svaki vektor je povezan sa originalnim dokumentom (metadata)
- Baza koristi specijalizovane indekse za brzu pretragu sličnosti
- Retrieval-Augmented Generation (RAG):
- Kada korisnik postavi upit, upit se također konvertuje u vektor
- Vektorska baza pronalazi najsličnije dokumente koristeći cosine similarity ili druge metrike
- Pronađeni dokumenti se prosleđuju LLM-u kao kontekst
- LLM generiše odgovor baziran na pronađenom kontekstu
- Prednosti:
- LLM dobija relevantan kontekst umjesto da se oslanja samo na svoje treniranje
- Omogućava ažuriranje znanja bez ponovnog treniranja modela
- Poboljšava tačnost i smanjuje "hallucinations" (izmišljene informacije)
# Konceptualni primjer RAG pipeline-a sa vektorskom bazom i LLM-om
# 1. Generisanje embeddings za dokumente
documents = [
"SQL Server je relacijska baza podataka",
"Vektorske baze koriste embeddings za pretragu",
"LLM modeli mogu generisati tekst"
]
# Koristimo embedding model (npr. OpenAI, Hugging Face)
embeddings = embedding_model.encode(documents)
# Rezultat: [[0.23, -0.45, 0.67, ...], [0.31, -0.12, 0.89, ...], ...]
# 2. Skladištenje u vektorsku bazu
vector_db.upsert(
vectors=embeddings,
ids=["doc1", "doc2", "doc3"],
metadata=[
{"title": "SQL Server", "category": "database"},
{"title": "Vector DB", "category": "database"},
{"title": "LLM", "category": "ai"}
]
)
# 3. Korisnikov upit
user_query = "Šta je baza podataka?"
query_embedding = embedding_model.encode([user_query])[0]
# 4. Pretraga sličnih vektora
similar_docs = vector_db.search(
query_vector=query_embedding,
top_k=2,
metric="cosine_similarity"
)
# Rezultat: [{"id": "doc1", "score": 0.89}, {"id": "doc2", "score": 0.76}]
# 5. Prosleđivanje konteksta LLM-u
context = "\n".join([documents[int(doc["id"][-1])-1] for doc in similar_docs])
llm_response = llm_model.generate(
prompt=f"Kontekst: {context}\n\nPitanje: {user_query}\n\nOdgovor:"
)
# LLM generiše odgovor baziran na pronađenom kontekstuŠta su Vektorski Embeddings?
Vektorski embeddings su numeričke reprezentacije podataka (tekst, slike, audio) u višedimenzionalnom prostoru. Slični elementi su pozicionirani blizu jedan drugom u ovom prostoru.
💡 Kako Embeddings Rade
Kada konvertujete tekst kao "SQL Server tutorial" u embedding, on postaje niz brojeva (npr., [0.23, -0.45, 0.67, ...]). Slični tekstovi proizvode slične vektore. Vektorske baze podataka mogu brzo pronaći slične vektore koristeći matematičke kalkulacije udaljenosti.
Kako se Podaci Snimaju u Vektorskim Bazama
Proces skladištenja podataka u vektorskim bazama podataka uključuje nekoliko koraka:
📥 Proces Skladištenja
- Preprocesiranje:
- Dokumenti se čiste i pripremaju (uklanjanje specijalnih karaktera, normalizacija)
- Dokumenti se mogu podijeliti u manje dijelove (chunks) za bolju preciznost
- Dodaju se metadata (naslov, autor, datum, kategorija)
- Generisanje Embeddings:
- Svaki dokument (ili chunk) se prosleđuje embedding modelu
- Model generiše vektor sa fiksnim brojem dimenzija (npr. 1536 za OpenAI ada-002)
- Vektor predstavlja semantičko značenje dokumenta u višedimenzionalnom prostoru
- Indeksiranje:
- Vektori se organizuju koristeći specijalizovane algoritme (HNSW, IVF, LSH)
- Kreira se struktura koja omogućava brzu pretragu sličnosti
- Metadata se čuva zajedno sa vektorima za filtriranje
- Skladištenje:
- Vektori se čuvaju u optimizovanom binarnom formatu
- Originalni dokumenti se mogu čuvati u bazi ili eksternom storage-u
- Kreira se mapiranje između vektora i originalnih dokumenata
📊 Vizualizacija Vektorskog Prostora

3D prikaz klastera podataka: Slični pojmovi su grupisani zajedno u višedimenzionalnom prostoru
Ilustracija: Dokumenti sa sličnim značenjem su blizu jedan drugom u vektorskom prostoru. Upit "baza podataka" pronalazi najbliže dokumente (SQL, DB, Data) koristeći cosine similarity.
# Primjer: Skladištenje dokumenata u vektorsku bazu
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
import openai
# 1. Inicijalizacija klijenta
client = QdrantClient("localhost", port=6333)
# 2. Kreiranje kolekcije
client.create_collection(
collection_name="documents",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
# 3. Dokumenti za skladištenje
documents = [
{
"id": 1,
"text": "SQL Server je relacijska baza podataka razvijena od strane Microsoft-a",
"metadata": {"category": "database", "author": "Microsoft"}
},
{
"id": 2,
"text": "Vektorske baze koriste embeddings za semantic search",
"metadata": {"category": "ai", "author": "AI Team"}
},
{
"id": 3,
"text": "PostgreSQL je napredna open-source relacijska baza",
"metadata": {"category": "database", "author": "PostgreSQL Team"}
}
]
# 4. Generisanje embeddings
embeddings = []
for doc in documents:
response = openai.Embedding.create(
input=doc["text"],
model="text-embedding-ada-002"
)
embedding = response['data'][0]['embedding'] # 1536 dimenzija
embeddings.append(embedding)
# 5. Skladištenje u vektorsku bazu
points = [
PointStruct(
id=doc["id"],
vector=embeddings[i],
payload={
"text": doc["text"],
**doc["metadata"]
}
)
for i, doc in enumerate(documents)
]
client.upsert(
collection_name="documents",
points=points
)
# 6. Pretraga sličnih dokumenata
query_text = "Šta je relacijska baza podataka?"
query_embedding = openai.Embedding.create(
input=query_text,
model="text-embedding-ada-002"
)['data'][0]['embedding']
results = client.search(
collection_name="documents",
query_vector=query_embedding,
limit=2
)
# Rezultat: Pronaći će dokumente 1 i 3 (o relacijskim bazama)
for result in results:
print(f"Score: {result.score}, Text: {result.payload['text']}")Kako Vektorske Baze Podataka Rade
Vektorske baze podataka koriste specijalizovane strukture indeksiranja za omogućavanje brzih pretraga sličnosti:
- Indeksiranje: Vektori se organizuju koristeći algoritme kao što su HNSW (Hierarchical Navigable Small World), IVF (Inverted File Index), ili LSH (Locality Sensitive Hashing)
- Pretraga Sličnosti: Kada postavite upit, baza podataka pronalazi vektore najbliže vašem upitnom vektoru
- Metrike Udaljenosti: Uobičajene metrike uključuju cosine similarity, Euclidean distance, i dot product
Šta Znači "B" Notacija?
"B" u B-tree i B+ tree stoji za "Balanced" ili "Bayer" (nazvano po izumitelju). Ovo su strukture podataka stabla korištene za indeksiranje:
- B-tree: Samo-balansirajuće stablo gdje svaki čvor može imati više djece. Korišteno u tradicionalnim bazama podataka za indeksiranje.
- B+ tree: Varijanta gdje su svi podaci pohranjeni u listovima, sa internim čvorovima koji sadrže samo ključeve. Efikasnije za range upite.
Vektorske baze podataka često koriste različite strukture optimizovane za visoko-dimenzionalne podatke, ali koncept balansiranih stabala za efikasno pretraživanje je sličan.
Vektorske Baze Podataka u Semantic Search
Semantic search razumije značenje i kontekst upita, ne samo podudaranje ključnih riječi. Vektorske baze podataka omogućavaju ovo kroz:
- Generisanje Embeddings: Konvertovanje dokumenata i upita u vektore
- Skladištenje: Čuvanje vektora dokumenata u vektorskoj bazi podataka
- Obrada Upita: Konvertovanje upita pretrage u vektor i pronalaženje sličnih vektora dokumenata
- Dohvaćanje: Vraćanje dokumenata sa najvišim skorom sličnosti
🔍 Semantic Search - Vizualizacija Procesa
Ilustracija: Upit "baza podataka" se konvertuje u vektor i pronalazi najbliže dokumente u vektorskom prostoru. Dokumenti sa sličnim značenjem (SQL, Database, Data) imaju visok cosine similarity skor i vraćaju se kao rezultati.
# Conceptual example (not actual SQL)
# 1. Convert documents to embeddings
document_embedding = embed("SQL Server is a relational database")
query_embedding = embed("database management system")
# 2. Find similar vectors
similar_documents = vector_db.search(
query_vector=query_embedding,
top_k=5,
metric="cosine_similarity"
)
# Returns documents about databases, even without exact keyword match
Poznate Vektorske Baze Podataka
📊 Poređenje Vektorskih Baza Podataka
| Baza Podataka | Tip | Ključne Funkcionalnosti | Najbolje Za |
|---|---|---|---|
| Pinecone | Managed Cloud | Potpuno upravljano, serverless, jednostavan API | Production AI aplikacije, startupi |
| Weaviate | Open Source / Cloud | GraphQL API, ugrađeni ML modeli, hibridna pretraga | Semantic search, knowledge graphs |
| Milvus | Open Source | Skalabilno, cloud-native, više tipova indeksa | Velika vektorska pretraga, enterprise |
| Qdrant | Open Source / Cloud | Rust-based, brzo, podrška za filtriranje | Visok performansna pretraga, filtriranje |
| pgvector | PostgreSQL Extension | Dodaje vektorsku podršku PostgreSQL-u | PostgreSQL korisnici koji trebaju vektorsku pretragu |
| Azure AI Search | Microsoft Cloud | Integrisano sa Azure-om, hibridna pretraga | Azure ekosistem, enterprise pretraga |
⚖️ SQL Server vs Druge Relacijske Baze Podataka
SQL Server je jedan od vodećih sistema za upravljanje relacijskim bazama podataka. Evo kako se poredi sa drugim popularnim opcijama:
📊 Tabela Poređenja SQL Server-a
| Funkcionalnost | SQL Server | MySQL | MariaDB | PostgreSQL | Oracle |
|---|---|---|---|---|---|
| Licenca | Commercial / Free Developer | Dual (GPL / Commercial) | GPL / LGPL | PostgreSQL License (BSD-like) | Commercial |
| Platforma | Windows, Linux, Docker | Windows, Linux, macOS | Windows, Linux, macOS | Windows, Linux, macOS, Unix | Windows, Linux, Unix |
| Performanse | Odlične, optimizovane za Windows | Vrlo dobre, read-heavy workloads | Vrlo dobre, MySQL-kompatibilne | Odlične, složeni upiti | Vodeće u industriji |
| Napredne Funkcionalnosti | In-Memory OLTP, Columnstore, JSON, Graph | JSON, Full-Text Search | Dynamic columns, JSON, GIS | Advanced indexing, JSON, Arrays, Extensions | Sveobuhvatne enterprise funkcionalnosti |
| Slučajevi Korištenja | Enterprise aplikacije, Windows ekosistem, Azure | Web aplikacije, LAMP stack | Web aplikacije, zamjena za MySQL | Složene aplikacije, data analytics | Velika preduzeća, mission-critical |
| Cijena | Besplatna Developer, plaćene Standard/Enterprise | Besplatna (GPL) ili Commercial licenca | Besplatna (open source) | Besplatna (open source) | Skupa (enterprise licenciranje) |
| Lakoća Korištenja | Odlični alati (SSMS, Azure Data Studio) | Dobro, jednostavna postavka | Dobro, MySQL-kompatibilno | Dobro, moćno ali složeno | Složeno, fokusirano na enterprise |
💡 Odabir Prave Baze Podataka
Odaberite SQL Server ako: Ste u Windows/Azure okruženju, trebate enterprise funkcionalnosti, želite odlične alate, ili gradite .NET aplikacije.
Odaberite MySQL/MariaDB ako: Trebate jednostavnu, brzu bazu podataka za web aplikacije, koristite LAMP/LEMP stack, ili trebate MySQL kompatibilnost.
Odaberite PostgreSQL ako: Trebate napredne funkcionalnosti, složene tipove podataka, ili želite moćnu open-source bazu podataka.
Odaberite Oracle ako: Imate enterprise zahtjeve, trebate maksimalne performanse, i imate budžet za licenciranje.
📄 NoSQL i Document Baze Podataka
NoSQL baze podataka su se pojavile da rješavaju ograničenja relacijskih baza podataka za određene slučajeve korištenja, posebno oko skalabilnosti i fleksibilnosti sheme.
Šta je NoSQL?
NoSQL znači "Not Only SQL" - ove baze podataka ne koriste tradicionalni relacijski model baziran na tabelama. Umjesto toga, koriste različite modele podataka optimizovane za specifične slučajeve korištenja.
Objašnjenje Document Baza Podataka
Document baze podataka čuvaju podatke kao dokumente, tipično u JSON ili BSON formatu. Svaki dokument je samostalan i može imati drugačiju strukturu od drugih dokumenata.
JSON (JavaScript Object Notation) - Detaljno Objašnjenje
JSON je lako čitljiv format za razmjenu podataka koji koristi tekstualnu reprezentaciju struktuiranih podataka. JSON je postao standardni format za razmjenu podataka između web aplikacija i servera, ali također može biti korišten kao format za skladištenje podataka u tekstualnim bazama podataka.
📋 JSON Karakteristike
- Tekstualni Format: JSON je čist tekst, lako čitljiv i razumljiv ljudima
- Struktura: Koristi parove ključ-vrijednost i ugniježđene objekte
- Tipovi Podataka: String, Number, Boolean, Array, Object, null
- Nezavisan od Platforme: Radi na bilo kojoj platformi i programskom jeziku
- Lako Parsiranje: Većina programskih jezika ima ugrađenu podršku za JSON
{
// String
"firstName": "John",
"lastName": "Doe",
// Number
"age": 30,
"salary": 75000.50,
// Boolean
"isActive": true,
"isAdmin": false,
// null
"middleName": null,
// Object (ugniježđeni)
"address": {
"street": "123 Main St",
"city": "New York",
"zipCode": "10001",
"country": "USA"
},
// Array
"skills": ["statistika", "analiza podataka", "SQL"],
// Array objekata
"projects": [
{
"projectId": "PROJ-001",
"name": "Digitalizacija statistike",
"startDate": "2023-01-15",
"budget": 2000000.00,
"status": "InProgress"
},
{
"projectId": "PROJ-002",
"name": "Popis stanovništva 2024",
"startDate": "2024-01-01",
"budget": 5000000.00,
"status": "InProgress"
}
],
// Kompleksniji primjer
"metadata": {
"createdAt": "2024-01-01T10:00:00Z",
"updatedAt": "2024-03-15T14:30:00Z",
"tags": ["statistika", "ekonomija", "državna agencija"]
}
}💾 JSON kao Tekstualna Baza Podataka
JSON fajlovi mogu se koristiti kao jednostavna tekstualna baza podataka, posebno za:
- Konfiguracijski fajlovi: Podešavanja aplikacije, podešavanja sistema
- Mali projekti: Aplikacije koje ne zahtijevaju kompleksne baze podataka
- Prototipiranje: Brzo testiranje ideja bez postavljanja baze podataka
- Statički podaci: Podaci koji se rijetko mijenjaju (npr. liste gradova, država)
- Backup i Export: Snimanje podataka u lako čitljivom formatu
Prednosti:
- Lako čitljiv i razumljiv
- Nema potrebe za posebnim serverom
- Jednostavno za verzioniranje (Git)
- Portabilan između sistema
Nedostaci:
- Nema ACID svojstva
- Nema istovremeni pristup (concurrency)
- Nedostaju napredne funkcionalnosti (indeksi, upiti)
- Nije efikasno za velike količine podataka
// users.json - Primjer jednostavne tekstualne baze podataka
[
{
"id": 1,
"username": "johndoe",
"email": "[email protected]",
"profile": {
"firstName": "John",
"lastName": "Doe",
"age": 30
},
"settings": {
"theme": "dark",
"notifications": true
}
},
{
"id": 2,
"username": "janedoe",
"email": "[email protected]",
"profile": {
"firstName": "Jane",
"lastName": "Doe",
"age": 28
},
"settings": {
"theme": "light",
"notifications": false
}
}
]BSON (Binary JSON) - Objašnjenje
BSON (Binary JSON) je binarna reprezentacija JSON-a dizajnirana za efikasno skladištenje i pretraživanje. BSON je format koji koristi MongoDB i druge NoSQL baze podataka za internu reprezentaciju dokumenata.
🔑 BSON vs JSON - Razlike
| Karakteristika | JSON | BSON |
|---|---|---|
| Format | Tekstualni (human-readable) | Binarni (binary) |
| Veličina | Veća (tekstualna reprezentacija) | Manja (kompaktna binarna forma) |
| Tipovi Podataka | String, Number, Boolean, Array, Object, null | Svi JSON tipovi + Date, Binary, ObjectId, Decimal128 |
| Čitljivost | Lako čitljiv ljudima | Nije čitljiv direktno (zahteva parsiranje) |
| Performanse | Sporije parsiranje | Brže parsiranje i skladištenje |
| Korištenje | Razmjena podataka, API-ji, konfiguracije | Interno skladištenje u MongoDB i drugim bazama |
// JSON format (kako vidite u editoru) - Zaposlenik u državnoj agenciji
{
"_id": "507f1f77bcf86cd799439011",
"firstName": "Ahmed",
"lastName": "Hodžić",
"jmbg": "0101950123456",
"email": "[email protected]",
"department": {
"departmentId": 4,
"departmentName": "Agencija za Statistiku",
"departmentCode": "AS"
},
"position": "Statističar",
"salary": 2500.00,
"hireDate": "2020-09-01",
"projects": [
{
"projectId": "PROJ-001",
"projectName": "Digitalizacija statistike",
"startDate": "2023-01-15",
"budget": 2000000.00
}
]
}
// BSON format (kako se čuva u MongoDB)
// Binarna reprezentacija koja uključuje:
// - Type informacije za svako polje
// - Length prefiksi za brzo parsiranje
// - Dodatne tipove (Date, Binary, ObjectId)
// - Kompaktniju strukturuKako Document Baze Podataka Rade
- Fleksibilnost Sheme: Svaki dokument može imati različita polja - nema rigidne sheme
- JSON/BSON Struktura: Podaci pohranjeni kao ugniježđeni objekti i nizovi
- Horizontalno Skaliranje: Dizajnirano za skaliranje preko više servera
- Jezik Upita: Svaka baza podataka ima svoj jezik upita (MongoDB koristi JavaScript-like upite)
- Indeksiranje: Može indeksirati bilo koje polje, uključujući ugniježđena polja
🔑 Prednosti Document Baza Podataka
- Fleksibilna Shema: Lako evoluirati strukturu podataka tokom vremena
- Prirodno Modeliranje Podataka: Dokumenti se dobro mapiraju na objekte aplikacije
- Brzi Razvoj: Nema potrebe za dizajniranjem složenih relacijskih shema
- Horizontalno Skaliranje: Može distribuirati podatke preko više servera
⚠️ Ograničenja Document Baza Podataka
- Nema Join-ova: Relacije moraju biti rješavane u kodu aplikacije
- Duplikacija Podataka: Povezani podaci često duplicirani kroz dokumente
- Konzistentnost: Eventual consistency model (ne uvijek ACID)
- Složeni Upiti: Neki upiti su teži nego u SQL-u
Poznate Document Baze Podataka
📊 Poređenje Document Baza Podataka
| Baza Podataka | Tip | Ključne Funkcionalnosti | Najbolje Za |
|---|---|---|---|
| MongoDB | Document Store | Najpopularnija, fleksibilna shema, bogat jezik upita | Web aplikacije, content management, katalozi |
| CouchDB | Document Store | Multi-master replikacija, RESTful API, offline podrška | Mobilne aplikacije, distribuirani sistemi, offline-first |
| Amazon DocumentDB | Managed Service | MongoDB-kompatibilna, potpuno upravljana, AWS integracija | AWS korisnici, upravljana MongoDB alternativa |
| Azure Cosmos DB | Multi-Model | Globalna distribucija, više API-ja (SQL, MongoDB, Gremlin) | Globalne aplikacije, multi-model potrebe, Azure ekosistem |
Kada Koristiti SQL vs NoSQL?
Izbor između SQL i NoSQL zavisi od vaših specifičnih zahtjeva:
💡 Vodič za Odluku
Koristite SQL (Relacijski) kada:
- Trebate ACID transakcije (finansijski podaci, inventar)
- Podaci imaju jasne relacije i strukturu
- Trebate složene upite sa join-ovima
- Integritet podataka je kritičan
- Gradite tradicionalne poslovne aplikacije
Koristite NoSQL (Document) kada:
- Trebate horizontalno skaliranje
- Shema je fleksibilna ili nepoznata
- Gradite content management, kataloge, ili korisničke profile
- Potreban je visok write throughput
- Podaci su slični dokumentima (JSON strukture)
🎯 Gdje SQL Server Stoji
SQL Server je relacijski sistem za upravljanje bazama podataka (RDBMS) koji se ističe u enterprise okruženjima, posebno unutar Microsoft ekosistema.

SQL Server u enterprise okruženju
Pozicija SQL Server-a
- Enterprise Nivo: Dizajniran za mission-critical aplikacije
- Windows Integracija: Duboka integracija sa Windows Server i Active Directory
- Azure Cloud: Native integracija sa Azure servisima
- .NET Ekosistem: Savršeno za .NET aplikacije
- Business Intelligence: Jaki BI alati (SSRS, SSAS, SSIS)
- Sigurnost: Enterprise nivo sigurnosnih funkcionalnosti
🔑 Prednosti SQL Server-a
- Odlični alati (SSMS, Azure Data Studio)
- Jake funkcionalnosti optimizacije performansi
- Sveobuhvatna sigurnost (enkripcija, row-level security, audit)
- Napredne funkcionalnosti (In-Memory OLTP, Columnstore, Graph, JSON)
- Odlična dokumentacija i podrška zajednice
☁️ Microsoft Azure i Cloud Baze Podataka
Microsoft Azure je cloud computing platforma koja pruža širok spektar servisa uključujući računarske resurse, skladištenje, mrežu, i naravno, baze podataka. Azure omogućava organizacijama da koriste baze podataka bez potrebe za održavanjem vlastite infrastrukture.

Microsoft Azure Cloud Platform
Šta je Azure i Kako se Uklapa u Ekosistem Baza Podataka?
Azure je Microsoft-ova cloud platforma koja nudi infrastrukturu kao servis (IaaS), platformu kao servis (PaaS), i softver kao servis (SaaS). U kontekstu baza podataka, Azure pruža:
🌐 Azure Cloud Modeli
- Infrastructure as a Service (IaaS):
- Kontrola nad virtualnim mašinama i infrastrukturom
- Možete instalirati vlastite instance SQL Server-a na VM-ovima
- Puna kontrola nad konfiguracijom i održavanjem
- Platform as a Service (PaaS):
- Upravljani servisi baza podataka (Azure SQL Database, Azure Cosmos DB)
- Microsoft upravlja infrastrukturom, ažuriranjima, i backup-om
- Vi se fokusirate samo na podatke i aplikacije
- Software as a Service (SaaS):
- Potpuno upravljani servisi (Azure SQL Managed Instance)
- Maksimalna automatizacija i minimalna administracija
Azure Baze Podataka - Pregled Dostupnih Opcija
Azure nudi širok spektar baza podataka za različite potrebe:
📊 Relacijske Baze Podataka na Azure
| Servis | Tip | Karakteristike | Najbolje Za |
|---|---|---|---|
| Azure SQL Database | PaaS | Upravljana SQL Server instanca, automatski backup, scaling | Cloud-native aplikacije, SaaS proizvodi |
| Azure SQL Managed Instance | PaaS | Potpuna SQL Server kompatibilnost, lift-and-shift migracije | Migracije iz on-premise, enterprise aplikacije |
| SQL Server na Azure VM | IaaS | Puna kontrola, custom konfiguracija, SQL Server licenca | Kompleksne migracije, legacy aplikacije |
| Azure Database for PostgreSQL | PaaS | Upravljana PostgreSQL instanca, open-source | PostgreSQL aplikacije, open-source stack |
| Azure Database for MySQL | PaaS | Upravljana MySQL instanca, LAMP stack podrška | Web aplikacije, WordPress, LAMP stack |
| Azure Database for MariaDB | PaaS | Upravljana MariaDB instanca, MySQL kompatibilna | MariaDB aplikacije, MySQL alternativa |
📄 NoSQL i Specializovane Baze na Azure
| Servis | Tip | Karakteristike | Najbolje Za |
|---|---|---|---|
| Azure Cosmos DB | Multi-Model | Globalna distribucija, više API-ja (SQL, MongoDB, Gremlin, Cassandra) | Globalne aplikacije, multi-model potrebe |
| Azure Table Storage | Key-Value | NoSQL key-value store, jeftino, visok throughput | Structured data, IoT, logging |
| Azure Blob Storage | Object Storage | Unstructured data, fajlovi, slike, video | Media storage, backup, archive |
| Azure Cache for Redis | In-Memory | Redis cache, session storage, real-time data | Caching, session management, real-time apps |
| Azure AI Search | Search Engine | Full-text search, semantic search, vector search | Search aplikacije, AI-powered search |
SQL Server na Azure - Varijante i Opcije
SQL Server ima nekoliko varijanti na Azure platformi, svaka optimizovana za različite scenarije:
🔷 Azure SQL Database
Karakteristike:
- Upravljani Servis: Microsoft upravlja infrastrukturom, ažuriranjima, i backup-om
- Elastično Skaliranje: Lako povećanje ili smanjenje resursa (DTU ili vCore modeli)
- Automatski Backup: Point-in-time restore, geo-replication
- Built-in Intelligence: Query performance insights, automatic tuning
- Serverless Opcija: Automatska pauza kada nije u upotrebi, plaćanje samo za korištenje
Najbolje za: Cloud-native aplikacije, SaaS proizvode, nove projekte
Ograničenja: Neki SQL Server funkcionalnosti nisu dostupne (npr. SQL Agent, FileStream)
🔷 Azure SQL Managed Instance
Karakteristike:
- Potpuna Kompatibilnost: 99% SQL Server funkcionalnosti
- Lift-and-Shift: Laka migracija postojećih aplikacija bez promjena koda
- Native VNet Podrška: Integracija sa Azure Virtual Network
- SQL Agent: Dostupan za automatizaciju zadataka
- Instance-Level Features: Cross-database queries, CLR, Service Broker
Najbolje za: Migracije iz on-premise, enterprise aplikacije koje zahtijevaju punu SQL Server funkcionalnost
Razlike od Azure SQL Database: Više funkcionalnosti, ali i viša cijena
🔷 SQL Server na Azure Virtual Machines
Karakteristike:
- Puna Kontrola: Kompletan pristup VM-u i SQL Server instanci
- Custom Konfiguracija: Potpuna kontrola nad setup-om i konfiguracijom
- Sve Funkcionalnosti: Sve SQL Server funkcionalnosti dostupne
- Licenciranje: Možete koristiti vlastitu licencu (BYOL) ili Azure Hybrid Benefit
- High Availability: Always On Availability Groups, Failover Cluster Instances
Najbolje za: Kompleksne migracije, legacy aplikacije, kada trebate punu kontrolu
Održavanje: Vi ste odgovorni za ažuriranja, backup, i održavanje
-- Azure SQL Database - Primjer konekcije
-- Connection string format:
-- Server=tcp:myserver.database.windows.net,1433;Database=mydb;
-- User ID=myuser@myserver;Password=mypassword;Encrypt=true;
-- Azure SQL Managed Instance - Primjer konekcije
-- Server=myserver.1234567890abc.database.windows.net;Database=mydb;
-- User ID=myuser;Password=mypassword;Encrypt=true;
-- SQL Server na Azure VM - Primjer konekcije
-- Server=myserver.eastus.cloudapp.azure.com,1433;Database=mydb;
-- User ID=myuser;Password=mypassword;Encrypt=true;
-- Svi koriste standardni SQL Server connection string format
-- Razlika je u server adresi i dostupnim funkcionalnostimaAzure i SQL Server - Integracija i Prednosti
Azure nudi nekoliko načina integracije SQL Server-a u cloud ekosistem:
🔗 Azure SQL Server Integracija
- Azure Active Directory:
- SQL Server autentifikacija kroz Azure AD
- Single sign-on (SSO) za aplikacije
- Centralizovano upravljanje pristupom
- Azure Key Vault:
- Centralizovano upravljanje tajnama i šifriranjem
- Transparent Data Encryption (TDE) sa Azure Key Vault
- Rotacija ključeva bez prekida servisa
- Azure Monitor i Log Analytics:
- Centralizovano praćenje performansi
- Query performance insights
- Automatsko otkrivanje anomalija
- Azure Backup i Disaster Recovery:
- Automatski backup sa retention policy
- Geo-replication za disaster recovery
- Point-in-time restore
- Azure Data Factory:
- ETL/ELT procesi za migraciju podataka
- Integracija sa drugim Azure servisima
- Orchestration data pipelines
💡 Kada Koristiti Koju Azure SQL Varijantu?
Koristite Azure SQL Database ako:
- Gradite novu cloud-native aplikaciju
- Trebate automatsko skaliranje i upravljanje
- Želite minimizirati administrativne zadatke
- Ne trebaju vam sve SQL Server funkcionalnosti
Koristite Azure SQL Managed Instance ako:
- Migrirate postojeću on-premise aplikaciju
- Trebate potpunu SQL Server kompatibilnost
- Koristite SQL Agent, Service Broker, ili druge instance-level features
- Želite upravljani servis ali sa više kontrole
Koristite SQL Server na Azure VM ako:
- Imate kompleksne zahtjeve za konfiguraciju
- Trebate pristup OS-u ili custom software
- Koristite Always On Availability Groups sa više instanci
- Želite maksimalnu kontrolu nad okruženjem
🎯 Praktična Vježba: Razumijevanje Tipova Baza Podataka
Vježba 1: Identifikacija Tipova Baza Podataka
Za svaki scenario ispod, identifikujte da li biste koristili relacijsku bazu podataka (SQL), document bazu podataka (NoSQL), ili vektorsku bazu podataka:
Scenario 1: Sistem za evidenciju zaposlenika sa odjeljenjima, projektima i izvještajima
Odgovor: SQL (Relacijski) - Zahtijeva jasne relacije između zaposlenika, odjeljenja i projekata. Potrebne su složene upite za statistiku i izvještavanje.
Scenario 2: Finansijski transakcioni sistem za banku
Odgovor: SQL (Relacijski) - Zahtijeva ACID transakcije i integritet podataka.
Scenario 3: AI-powered search engine koji pronalazi slične dokumente
Odgovor: Vektorska Baza Podataka - Dizajnirana za pretragu sličnosti i embeddings.
Scenario 4: Skladištenje korisničkih profila sa različitim poljima po korisniku
Odgovor: NoSQL (Document) - Fleksibilna shema omogućava različita polja po korisniku.
Vježba 2: Priprema za SQL Server Setup
Prije prelaska na Modul 1, osigurajte da razumijete:
- ✅ Šta je relacijska baza podataka
- ✅ Zašto je SQL Server dobar izbor za enterprise aplikacije
- ✅ Razliku između SQL i NoSQL baza podataka
- ✅ Šta su vektorske baze podataka i kada se koriste
✅ Zaključak
U ovoj lekciji ste naučili osnove baza podataka:
- ✅ Šta su baze podataka i zašto postoje
- ✅ Tipove baza podataka: Relacijske (SQL), NoSQL, i Vektorske baze
- ✅ Kako vektorske baze podataka rade i njihovu ulogu u AI aplikacijama
- ✅ Poziciju SQL Server-a u odnosu na druge relacijske baze podataka
- ✅ Document baze podataka i kada koristiti NoSQL vs SQL
- ✅ Gdje SQL Server stoji u ekosistemu baza podataka
📚 Sljedeća Lekcija
U Modulu 1.1, naučićete kako postaviti SQL Server 2022, instalirati development alate, i razumjeti SQL Server ekosistem. Ovo će vas pripremiti za praktični rad sa SQL Server-om.